Bolt BlogTech BlogCUPED for switchback testsCUPED for switchback testsTech BlogThemeShare8 min read • Sep 4, 2024Tech Blog
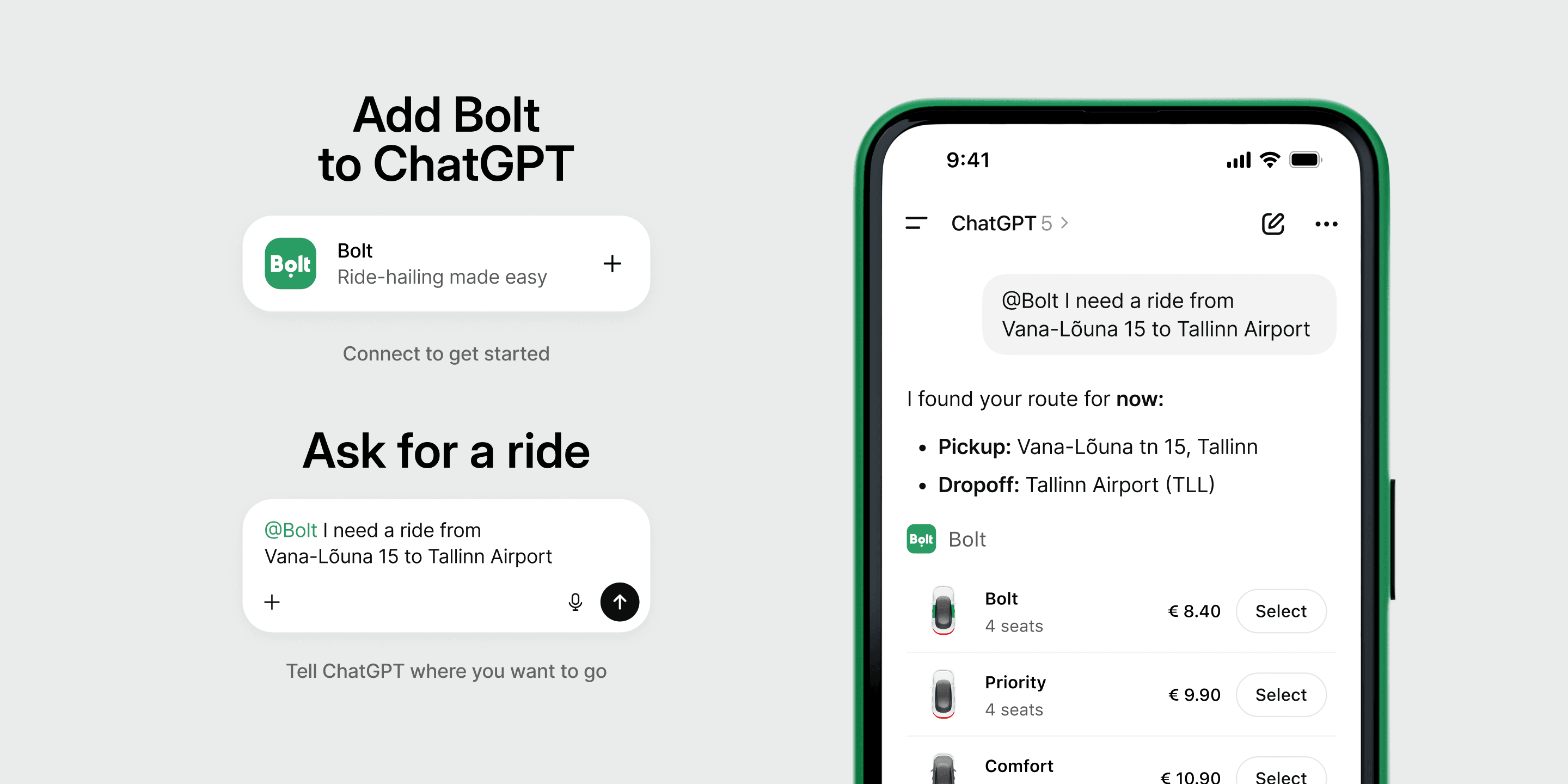
Press releasesJul 29, 2026Bolt launches ride-hailing integration to ChatGPTBolt becomes the first platform to bring ride-hailing through AI to EU, UK, Norway, Switzerland, Ukraine and Azerbaijan.